Independent research prepared for PingAlert found that agency monitoring teams are not struggling with uptime checks alone. The biggest operational drag is what happens around the checks: too many alerts, too little client-ready reporting, and too much friction across multi-client workflows.
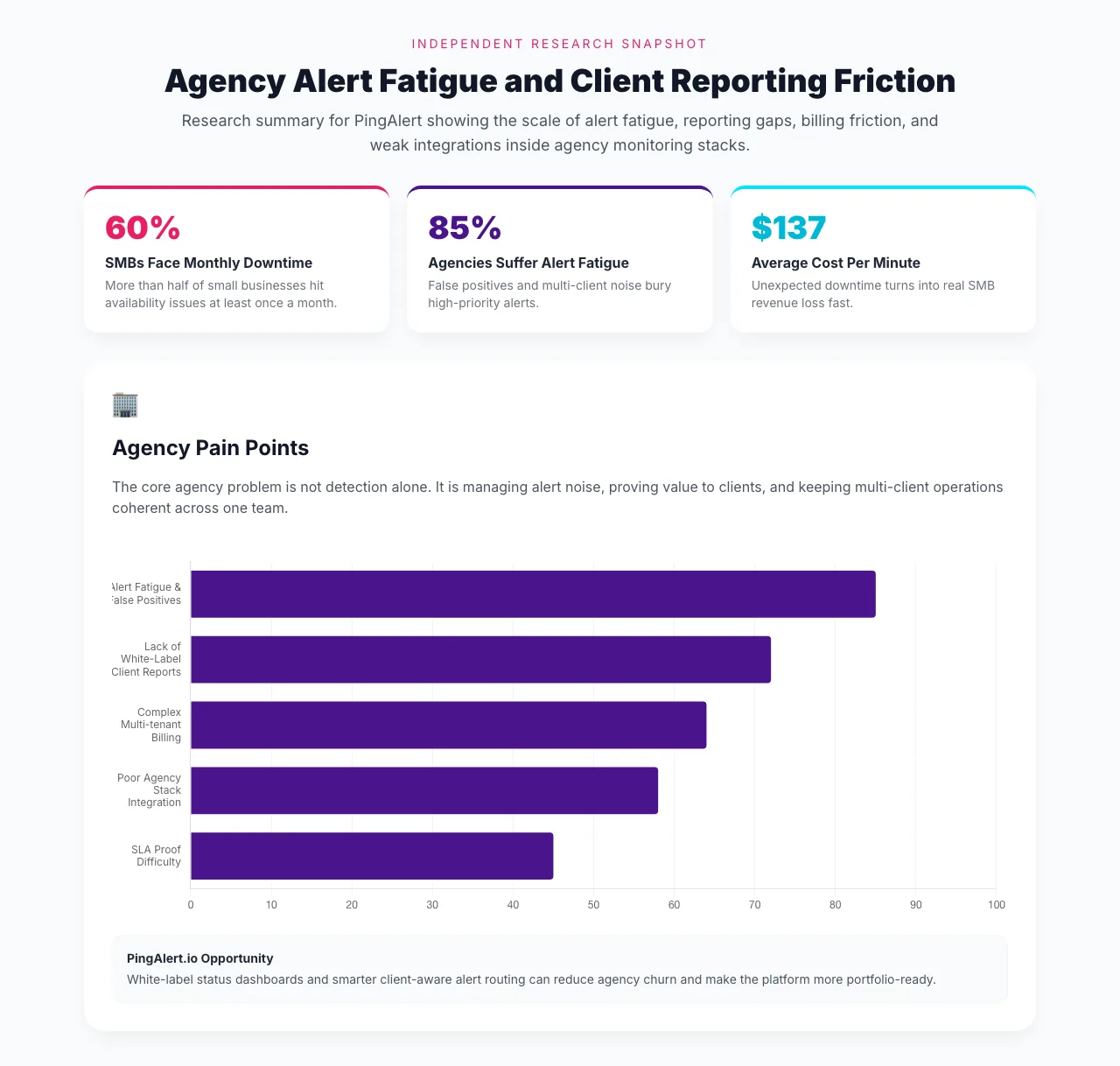
The same research snapshot also reinforces the business pressure behind the problem: 60% of SMBs in the study face monthly downtime, agency operators report severe alert fatigue, and the estimated SMB outage cost reaches $137 per minute. For agencies serving those businesses, noisy monitoring turns directly into slower response and shakier retention.
Research Snapshot: What Agency Teams Say Hurts Most
The agency chart in the research ranks five recurring pain points:
- Alert fatigue and false positives: 85%
- Lack of white-label client reports: 72%
- Complex multi-tenant billing: 64%
- Poor agency stack integration: 58%
- SLA proof difficulty: 45%
This is the key takeaway: agency pain is operational, not theoretical. The most urgent complaints are about signal quality, client communication, and proving service value across multiple accounts.
Why Alert Fatigue Hits Agencies Harder Than Other Teams
In-house monitoring teams usually support one product. Agencies support many clients, often with the same responders, the same Slack channels, and the same hours in the day.
That creates a compounding effect:
- One infrastructure issue can trigger dozens of client alerts.
- False positives burn trust in the alerting system itself.
- Account managers need updates before engineers have full diagnosis.
- Client reporting becomes harder when the underlying incident stream is noisy.
This is why agency uptime monitoring needs cleaner correlation logic, not just more endpoints and more notifications.
The Research Workflow Worth Watching: Smart Alert Grouping
One part of the research is especially useful because it turns the abstract problem into a concrete workflow: smart alert grouping.
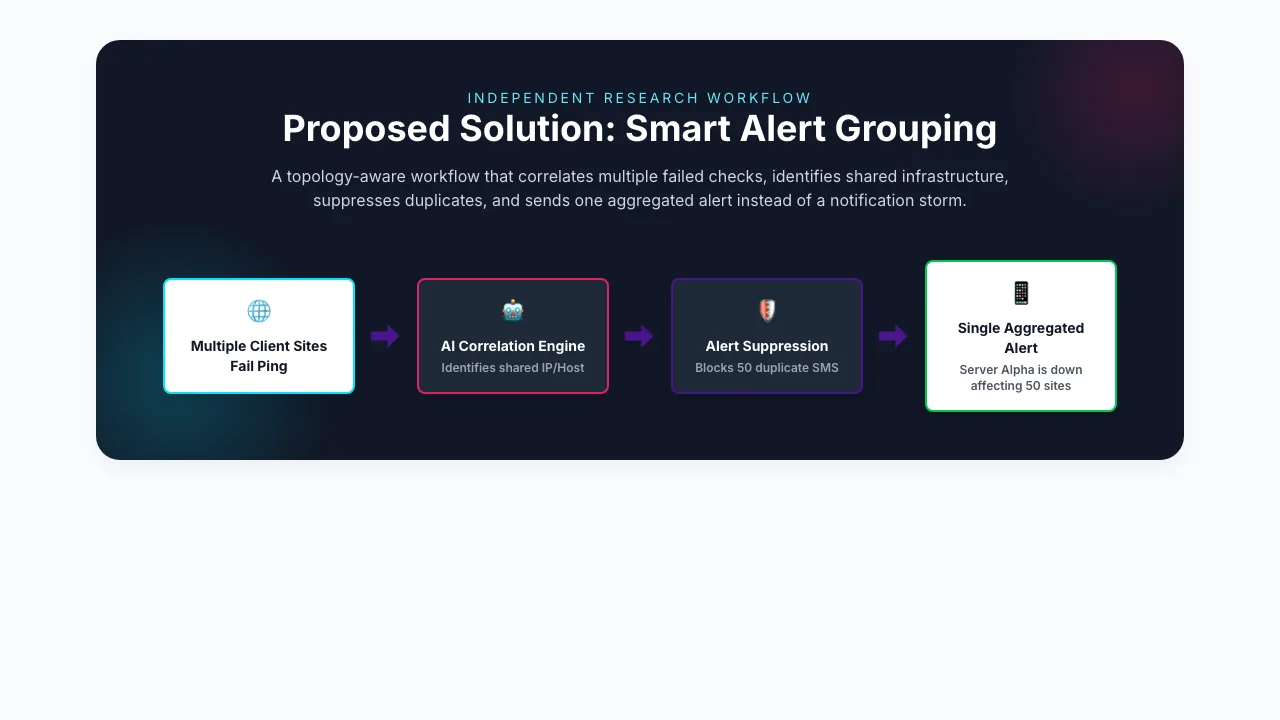
The workflow is simple:
- Multiple client sites fail checks at the same time.
- A correlation layer identifies shared infrastructure, such as a common IP or host.
- Duplicate alerts are suppressed instead of sent one by one.
- The team receives one aggregated alert, for example:
Server Alpha is down affecting 50 sites.
For agencies, this matters because the real failure is rarely "too little monitoring." The real failure is notification storms that hide the root cause behind a wall of duplicates.
What This Research Suggests Without Turning It Into a Matrix
The research also points to three practical themes agencies care about immediately:
- Reduce false positives before adding more checks.
- Make client communication and reporting easier to ship under your own brand.
- Connect alerts to client ownership instead of broadcasting everything to everyone.
That lines up closely with the existing PingAlert content around website monitoring for agencies, white-label status pages for agencies, and client reporting for agencies.
Reader Questions, Answered
What is alert fatigue in agency monitoring?
Alert fatigue happens when teams receive so many repeated, low-quality, or duplicate notifications that real incidents become harder to triage quickly. In agencies, the problem grows faster because one team often supports many clients at once.
Why do white-label reports matter so much to agencies?
Because agencies are selling reliability as a service, not just using monitoring internally. If the reporting experience is weak or obviously generic, it becomes harder to prove value in monthly reviews and renewals.
How does smart alert grouping reduce notification storms?
It correlates related failures, identifies shared infrastructure, and sends one aggregated alert instead of dozens of duplicate messages. That improves triage speed and makes incident response calmer.
Wrap Up
The research is clear: agency monitoring friction is dominated by noise, reporting gaps, and fragmented workflows. Teams that solve alert quality and client-facing clarity first will get more value from every monitor they already run.
Ready to run calmer multi-client monitoring with clearer reporting and stronger incident workflows?
Related guides:
- Website monitoring for agencies
- Client reporting for agencies
- White-label status pages for agencies
- Agency incident response playbook
Sources and references
- Independent research snapshot provided to PingAlert editorial team, March 2026
- Charts and workflow visuals in this article are reproduced from that research source