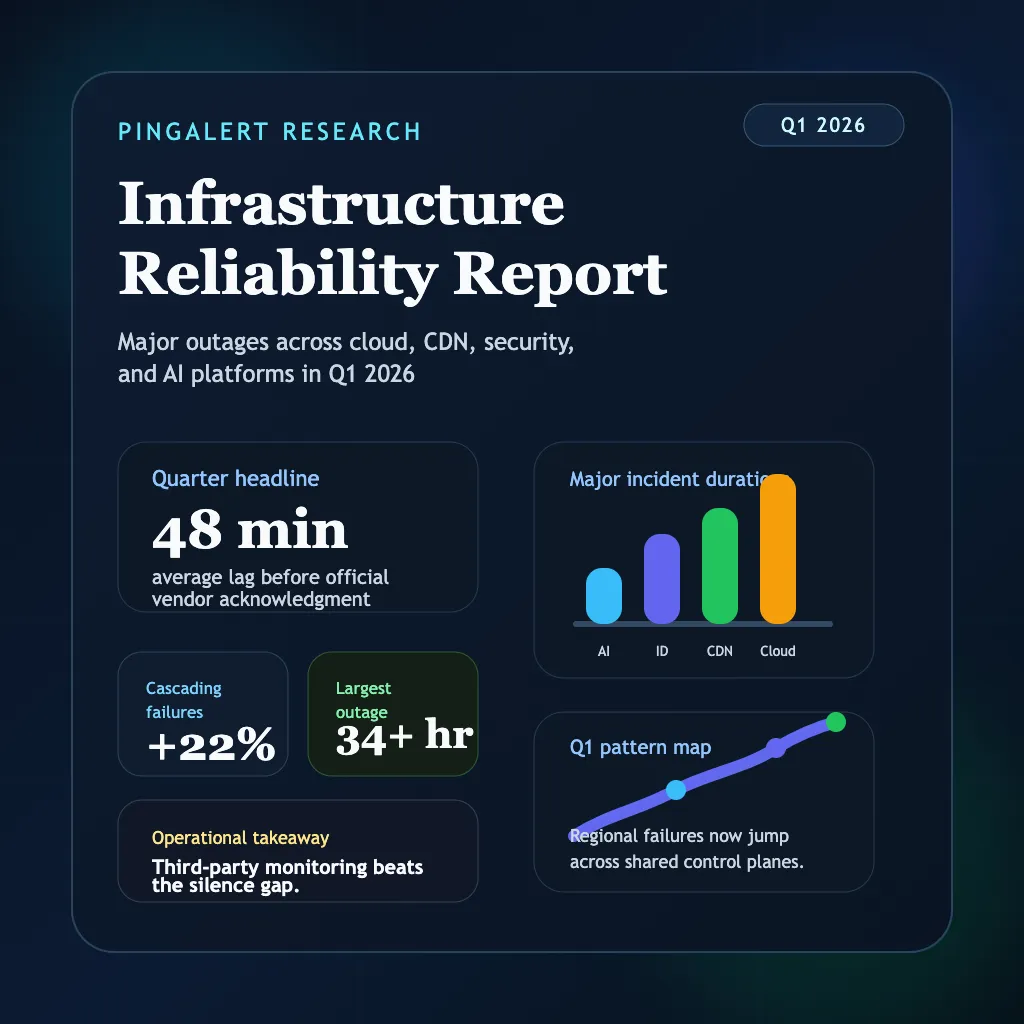
Q1 2026 made one pattern hard to ignore: teams that waited for vendor status pages lost time, trust, and often money. Across cloud platforms, CDNs, identity providers, and AI services, the biggest outages were not just long. They were unevenly communicated, operationally noisy, and expensive to diagnose from inside the blast radius.
Direct Answer
The quarter's clearest lesson is simple: if your product depends on third-party infrastructure, you need independent monitoring and a repeatable communication workflow. Q1 2026 was defined as much by delayed acknowledgment and confusing dependency chains as by raw outage duration.
Why This Matters
The report was written for teams that depend on outside platforms but still own the customer relationship:
- IT ops teams that run primary and backup infrastructure across multiple vendors
- Dev and DevOps teams shipping user-facing workflows on cloud and AI APIs
- Security leads whose login, verification, and perimeter controls depend on external providers
- Business owners and executives who need faster detection, faster updates, and clearer exposure reporting
In practice, the business risk is not only downtime. It is the silence between failure onset and clear public acknowledgment. That is the period where support queues expand, internal teams guess, and customers decide whether they still trust you.
Q1 2026 by the Numbers
- The report tracked a 22% increase in cascading failures across major digital infrastructure providers.
- The average "trust gap" between service degradation and official acknowledgment was framed at 48 minutes.
- The report estimates that delayed detection, delayed communication, and outage impact cost enterprises roughly $1.2B in Q1 alone.
- The largest cloud event of the quarter was the March 1-2 AWS incident, which stretched beyond 34 hours.
- AI platform instability created a new operating risk for teams that now treat model access as production infrastructure.
Q1 2026 Outage Summary Table
| Category | Service | Date(s) | Duration | Root Cause / Impact |
|---|---|---|---|---|
| Cloud Platforms | AWS | Mar 1-2 | 34+ hours | Physical damage in the UAE cascaded into broader S3 and EC2 disruption. |
| Azure | Feb 2 | 10 hours | Storage account misconfiguration hit CI/CD pipelines and adjacent workloads. | |
| Google Cloud | Jan 15 | 45 minutes | Regional latency event and the quarter's least disruptive major cloud incident. | |
| Microsoft 365 on Azure | Jan 22 | 9 hours | Global infrastructure slice failure affected Teams and Outlook. | |
| Web Hosting and CDN | Cloudflare | Feb 20 | 6 hours 7 minutes | BGP prefix withdrawal disrupted routing and exposed dependency concentration. |
| GoDaddy | Mar 16 | 3 hours 59 minutes | DNS resolution failures tied to unresponsive name servers. | |
| Namecheap | Mar 30 | 9 hours 3 minutes | Temporary network issues on a premium hosting cluster. | |
| Akamai | Jan 12 | 2 hours | Edge DNS instability affected major streaming paths. | |
| Security and Identity | Okta | Jan 22 | 10 hours | Third-party email provider outage disrupted identity verification. |
| Duo Security | Feb 3 | 1 hour 35 minutes | Microsoft Entra-related 504 errors caused login failures. | |
| Zscaler | Mar 23 | 5 hours 38 minutes | Dubai and Abu Dhabi routing issues disrupted EMEA traffic. | |
| Cloudflare security services | Feb 20 | 6 hours 7 minutes | WAF and identity blind spots appeared during the core CDN outage. | |
| AI and ML Platforms | OpenAI | Feb 3-4 | About 48 hours | Intermittent errors in a high-demand traffic window impacted production usage. |
| Claude | Mar 2 and Mar 27 | 5-8 hours | Separate failures tied to AWS dependency and later capacity overload. | |
| Grok | Jan 27 | 7.5 hours | Social-data pipeline synchronization failure. | |
| Gemini | Feb 12 | 1 hour | Rollout-related token processing delay during a model update. |
What Different Teams Should Change
IT Ops and Reliability Teams
- Monitor backup systems with the same rigor as primaries.
- Track vendor dependencies by region, not just by provider name.
- Define a target for time to first public update, not only time to mitigation.
Product and Dev Teams Building with AI
- Treat model providers as external production dependencies with failover rules.
- Decide in advance when to reroute traffic to a secondary model.
- Instrument customer-visible failure states instead of waiting for vendor confirmation.
Security and Identity Teams
- Assume identity and edge outages create temporary blind spots in access control and verification.
- Add alerts for critical login, MFA, and verification flows from an outside network path.
- Keep an incident mode that narrows change volume during vendor instability.
Executives and Business Owners
- Ask for detection time, first-update time, and dependency concentration in every outage review.
- Do not treat public status pages as your first signal.
- Measure trust loss, support overhead, and recovery communication as part of outage cost.
Simple Q1 2026 Downtime Calculator
The report uses a simple framework that any team can adapt:
Total outage cost = (hours x revenue impact per hour) + (hours x response labor per hour)
Example assumptions from the report:
- Small business:
$250/hrrevenue impact plus$100/hradmin response cost - Mid-market:
$2,500/hrrevenue impact plus$500/hrdevelopment response cost - Enterprise:
$25,000/hrrevenue impact plus$2,000/hrSRE response cost
Using that model, a 34-hour AWS event for a mid-market company works out to:
(34 x 2500) + (34 x 500) = $102,000
The exact number will vary by business, but the exercise is useful because it turns "vendor outage risk" into a planning number instead of a vague concern.
How to Beat the Trust Gap
The biggest Q1 failures were amplified by silence. Teams that want to reduce that gap should make a few operating changes now:
- Monitor critical vendors and customer-facing endpoints from outside your own infrastructure.
- Set a first-update target of 10 to 15 minutes for high-impact incidents.
- Separate internal debugging notes from external customer language.
- Keep failover triggers ready for DNS, status page updates, webhook automations, or model routing changes.
- Review vendor outage patterns quarterly so dependency risk stays visible.
Third-party monitoring matters because it gives you a signal before official messaging catches up. That matters most when the provider status page is late, partial, or unavailable during the incident itself.
Reader Questions, Answered
What caused the AWS outage in March 2026?
The report attributes it to a physical data-center incident in the UAE region that cascaded into broader control-plane and service disruption.
How long did the February 2026 Cloudflare outage last?
The report records the Cloudflare event at 6 hours and 7 minutes, tied to a BGP routing issue.
Why is vendor status not enough during major outages?
Because public vendor communication often lags real customer impact. Teams still need their own external signal to detect failures, assess blast radius, and communicate sooner.
Why were AI outages especially important in Q1 2026?
Because many teams now use external models as production infrastructure. When a model provider fails, customer workflows can break just as directly as they would during a cloud or DNS incident.
What is the simplest action to take after reading this report?
Inventory your critical third-party dependencies, monitor them independently, and define who publishes the first customer update when a vendor outage hits.
Wrap Up
Q1 2026 was a reminder that availability is only part of reliability. Detection speed, communication speed, and dependency awareness are just as important when customers experience the outage before the vendor acknowledges it.
Ready to detect third-party outages faster and communicate with more confidence?
Start your free trial on PingAlert
Related guides:
- How synthetic monitoring helps and why it is important
- Status page incident communication workflow: what to publish in the first 60 minutes
- Website, API, and uptime monitoring priority checklist
Sources and references
- PingAlert Q1 2026 outage research report compiled from public vendor status pages, incident communications, and post-incident notes published between January 1, 2026 and March 31, 2026.
- Vendor communications reviewed in the source report covered AWS, Microsoft Azure and Microsoft 365, Google Cloud, Cloudflare, GoDaddy, Namecheap, Akamai, Okta, Duo Security, Zscaler, OpenAI, Anthropic Claude, xAI Grok, and Google Gemini.