When production issues hit, early decisions shape the full incident timeline. Teams with a repeatable first-30-minute workflow usually reduce chaos, speed recovery, and communicate better.
Direct Answer: The First 30-Minute Workflow
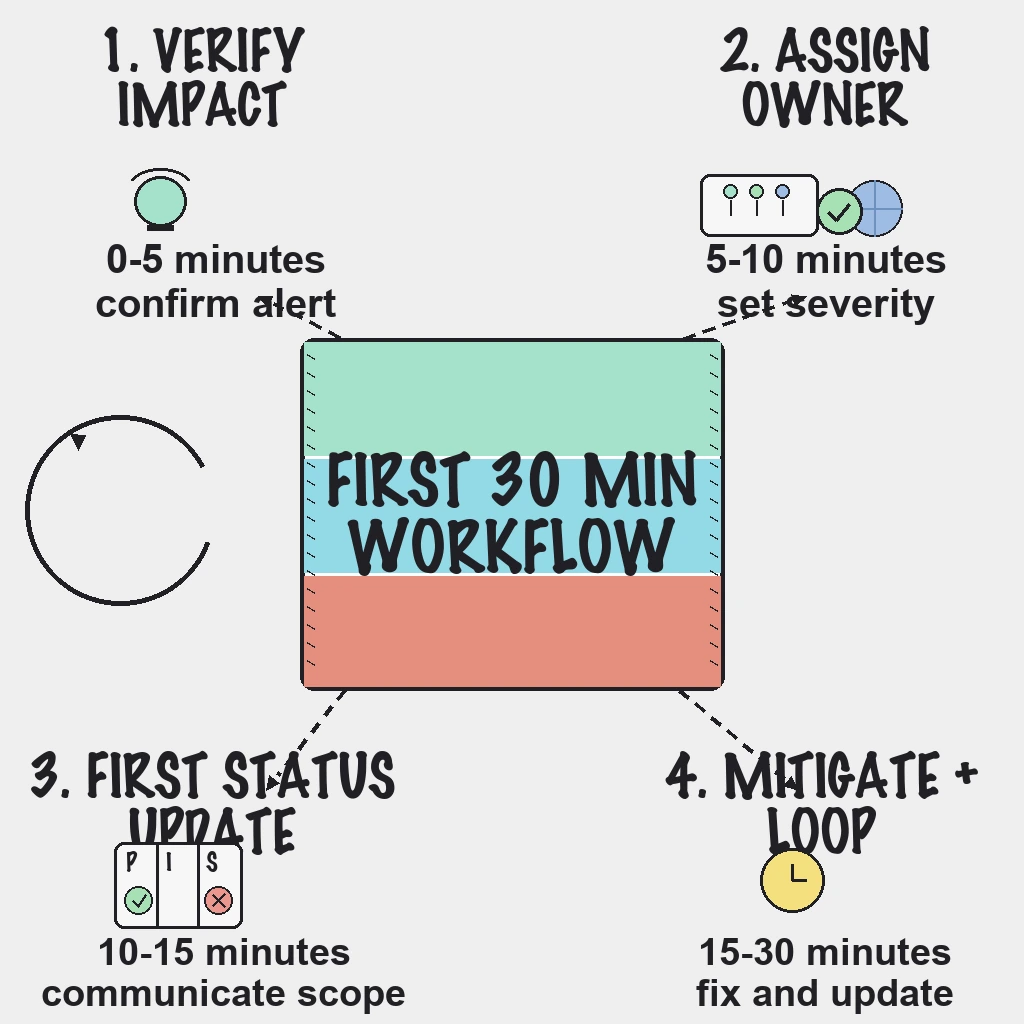
- Minutes 0-5: Validate alert with at least two signals.
- Minutes 5-10: Assign incident owner and severity by impact.
- Minutes 10-15: Publish first status update with scope and next update time.
- Minutes 15-30: Run mitigation loop and timed communication updates.
Severity Model That Prevents Over-Paging
- SEV1: Broad customer impact or revenue-critical outage.
- SEV2: Partial degradation with active customer impact.
- SEV3: Limited or internal impact.
Add confidence before paging:
- High: Multi-region failures + elevated errors.
- Medium: Single-region or dependency symptoms.
- Low: Single-probe anomaly only.
Actionable Checklist
Pre-incident readiness
- Define incident owner by shift.
- Route alerts by severity and service criticality.
- Keep status page components and subscriber lists ready.
- Review SSL/domain expiry monitoring weekly.
During incident
- Confirm real customer impact before broad escalation.
- Publish first external update within 10-15 minutes.
- Include next update timestamp in every message.
- Log decisions and rollback points in one channel.
After incident
- Publish customer-facing closure summary.
- Complete RCA within a fixed window.
- Track prevention tasks with owners and due dates.
Customer Update Template (Short Form)
- Investigating: investigating impact on
[service], next update in 30 minutes. - Identified: issue identified in
[component], mitigation in progress. - Monitoring: fix deployed, stability under observation.
- Resolved: service stable, follow-up prevention actions scheduled.
Reader Questions, Answered
What should be in the first status page update?
Affected service, visible customer impact, incident start window, and next update time.
How often should updates be posted?
Every 15-30 minutes during active high-impact incidents.
Should every alert page after hours?
No. Page when confidence and customer impact are both high.
Wrap Up
The first 30 minutes of incident response should be procedural, not improvised.
Ready to standardize your SaaS incident workflow with faster communication and calmer on-call?
Start your free trial on PingAlert
Related guides:
- Incident follow-through workflow
- Status page incident communication workflow
- MSP uptime monitoring playbook